



データが少なくても分析を可能にする「スパース推定」
データサイエンスの2つの目的
データを分析する「データサイエンス」と呼ばれる学問の中で、近年、特に膨大な量の情報「ビッグデータ」をAI(人工知能)に学習させる「ディープラーニング」に関する研究が進んでいます。適用される分野も、経営、自動運転、病気の診断、遺伝子解析など、あらゆる分野に広がりつつあります。
データサイエンスに関する研究には、大きく2つの目的があります。1つはデータから法則性を見いだし、問題の原因を特定したり、課題の解決法を見つけたりする手法の開発、もう1つは情報処理の性能をアップするための手法の開発です。処理性能がアップすれば、それだけ大量のデータを短時間で分析できることになり、効率がアップします。
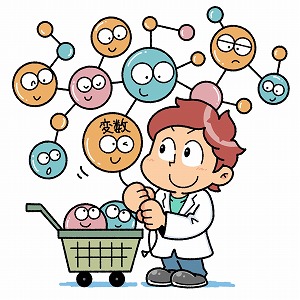
どの変数が大事なのか
一般的には、データのサンプル数が多ければ多いほど、解析結果の精度は上がります。データの中には多くの変数が含まれ、それぞれの変数の相関関係を分析する必要があります。変数とは、条件によって変化する数値です。例えば、ある店舗の売り上げを増やすために、どんな要素が重要なのかを分析するとします。関係しそうな要素としては、「商品の点数」「商品の値段」「店舗の広さ」「駅からの距離」などが考えられますが、これら要素が変数です。数多くのデータがあれば、どの要素が売り上げとの相関関係が強いのかを分析することが容易になります。
「スパース推定」で変数を絞る
ただし、状況や分野によっては、たくさんデータが取れない場合があります。例えば、難病の治療データなどは、サンプル数が少ないため、「ビッグデータ」と呼ぶほどのデータが取れません。そうした場合には、「スパース推定」と呼ばれる手法が使われます。それぞれの変数をばらばらなものではなくネットワークとしてとらえることで、多数の変数の中から重要と推定される変数を選択して、シンプルな数理モデルを作るという方法です。これによって、多くのサンプルを得にくい分野においても、データ分析が可能になるのです。
関連する
SDGs
![選択:[SDGsアイコン目標4]](https://telemail.jp/shingaku/requestren/img/data/SDGs-4-active.png )
![選択:[SDGsアイコン目標9]](https://telemail.jp/shingaku/requestren/img/data/SDGs-9-active.png )
※夢ナビ講義は各講師の見解にもとづく講義内容としてご理解ください。
※夢ナビ講義の内容に関するお問い合わせには対応しておりません。
先生情報 / 大学情報

大阪大学 基礎工学部 情報科学科 数理科学コース 教授 鈴木 讓 先生
興味が湧いてきたら、この学問がオススメ!
統計学、データサイエンス先生が目指すSDGs
先生への質問
- 先生の学問へのきっかけは?
- 先輩たちはどんな仕事に携わっているの?
